Doctor GPT-3: hype or reality?

Kevin Riera
Machine Learning Engineer

Anne-Laure Rousseau, MD
Cardio-vascular doctor

Clément Baudelaire
ML Product Manager
You may have heard about GPT-3 this summer, the new cool kid on the AI block. GPT-3 came out of OpenAI, one of the top AI research labs in the world which was founded in late 2015 by Elon Musk, Sam Altman and others and later backed with a $1B investment from Microsoft.
You’ve probably also heard about the ongoing AI revolution in healthcare, thanks to promising results in areas such as automated diagnosis, medical documentation and drug discovery, to name a few. Some have claimed that algorithms now outperform doctors on certain tasks and others have even announced that robots will soon receive medical degrees of their own! This can all sound far-fetched... but could this robot actually be GPT-3?
Our unique multidisciplinary team of doctors and machine learning engineers at Nabla had the chance to test this new model to tease apart what’s real and what’s hype by exploring different healthcare use cases.
But first, coffee
In machine learning, a language model like GPT-3 simply tries to predict a word in a sentence given the previous words, called the context. It’s a supercharged autocomplete system like the one you may use with Gmail. Being able to predict the next word in a sentence seems deceptively simple at first, but this actually enables many compelling use cases, such as chatbots, translation or Q&A.
At the time of writing, GPT-3 is the most complex language model ever trained, with a whopping 175 billion parameters in total - that’s as many knobs that are fine-tuned over weeks of intensive cloud computing to make the AI magic work. Certainly a huge number, but still way below the 100 (or maybe 1000+) trillion synapses in the human brain that enable reasoning, perception and emotions.
Thanks to the large size of the model, GPT-3 can be applied on new tasks and ‘few-shot’ demonstrations without any further fine-tuning on specific data. In practice, this means the model can successfully understand the task to perform with only a handful of initial examples. This property is a huge improvement compared to previous, less complex language models, and is much closer to actual human behavior - we don’t need thousands of examples to distinguish a cat from a dog.
Despite obvious biases learned from the data used for training - basically books plus the whole Internet, from Wikipedia to the New York Times - GPT-3’s ability to transform natural language into websites, create basic financial reports, solve langage puzzles, or even generate guitar tables has been very promising so far. But what about healthcare?
Then, the obvious disclaimer
As Open AI itself warns in GPT-3 guidelines, healthcare “is in the high stakes category because people rely on accurate medical information for life-or-death decisions, and mistakes here could result in serious harm”. Furthermore, diagnosing medical or psychiatric conditions falls straight in the “unsupported use” of the model. Despite this we wanted to give it a shot and see how it does on the following healthcare use cases, roughly ranked from low to high sensitivity from a medical perspective: admin chat with a patient, medical insurance check, mental health support, medical documentation, medical questions & answers and medical diagnosis. We also looked at the impact of some parameters of the model on the answers - spoiler alert, it’s fascinating!
GPT-3, your next medical assistant?
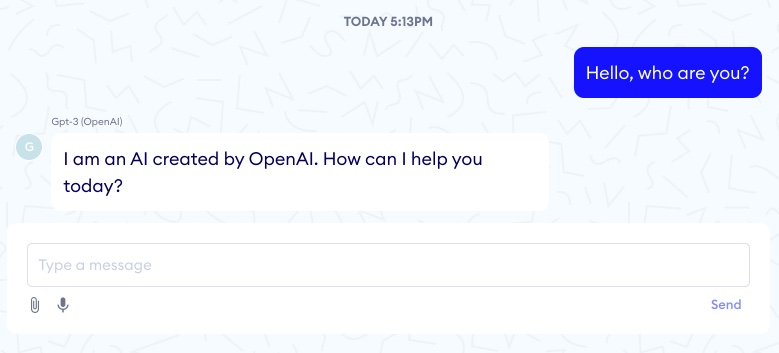
Our first tests showed that GPT-3 seemed to work for basic admin tasks such as appointment booking, but when digging a bit we found that the model had no clear understanding of time, nor any proper logic. Its memory also sometimes fell short - for the appointment in the example below, the patient’s initial 6pm constraint is overlooked as GPT-3 suggests booking for 7pm after a few messages.
What about insurance checks?
Similar to the admin tasks above, GPT-3 could help nurses or patients to quickly find a piece of information in a very long document, like finding insurance benefits for specific medical examinations. In the example below we seeded the model with a 4-page standard benefits table that shows a $10 copay for an X-ray, $20 for an MRI exam, and then asked 2 simple questions. GPT-3 was able to get the copay for an X-ray but could not sum up the copays for several exams, which again highlights a lack of basic reasoning.

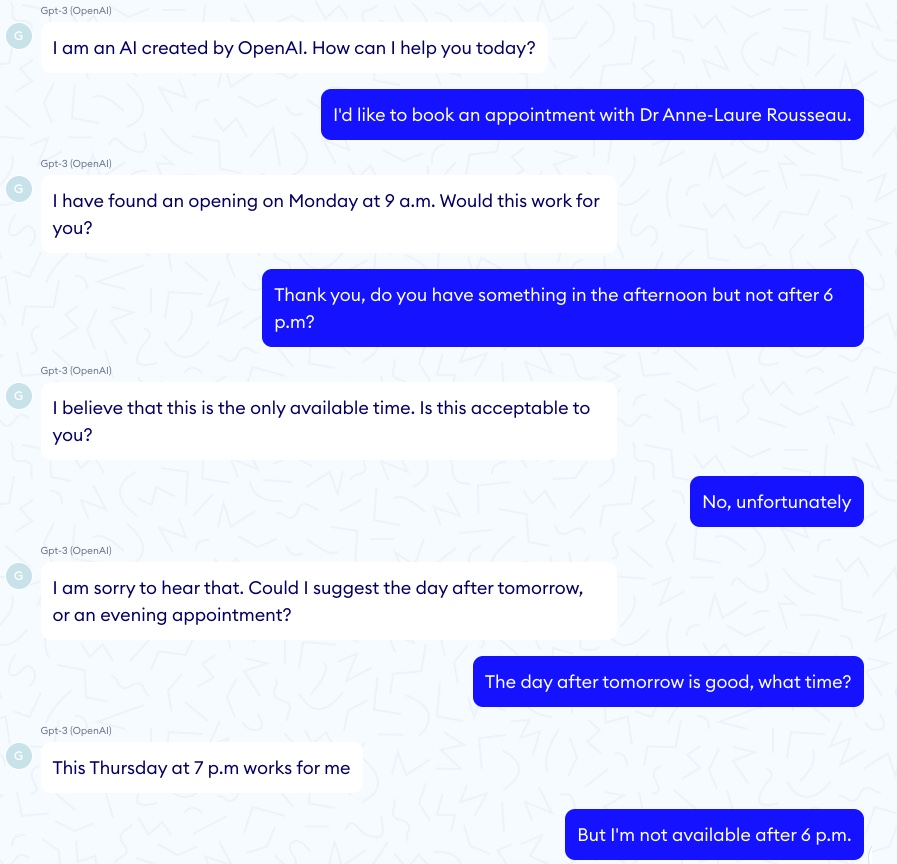
Recycle to relieve stress!
Relax on your living room sofa and talk, GPT-3 will listen to your problems endlessly and may even give you some actionable tips! This is probably one of the best use cases for GPT-3 in healthcare, and it’s not so surprising given the already good results from the Eliza algorithm back in 1966, which managed to give a human touch with only pattern matching rules operating behind the scenes.
One key difference between the two approaches though is that rule-based systems like Eliza were in full control of the computer’s response. In other words, we are certain that nothing potentially harmful could be said.
This contrasts with the example below in which GPT-3 sadly tells us that committing suicide is a good idea…

The model can also shoot unexpected answers where it suggests recycling more to ease stress - using a rationale which, while being convoluted, is actually quite sensible!
Medical documentation
GPT-3 has already shown promising results in summarizing and simplifying text, something that could be very useful for patients to understand medical reports often full of jargon, or for doctors to quickly get the gist of a patient’s long medical history. Well, GPT-3 is probably not quite ready for this (yet?). Our tests show dangerous oversimplifications, difficulties to associate causes and consequences, and once again a lack of basic deductive reasoning.
Medical Q&A: not as good as good ol’ Google yet
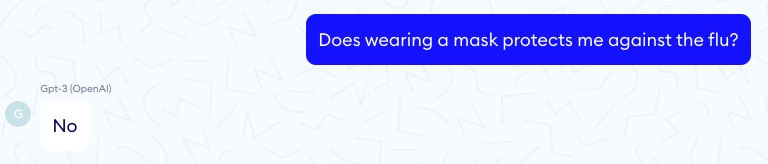
When looking for specific scientific information, drug dosages or prescription support, our experiments show that GPT-3 is not reliable enough to be safely used as a trustworthy support tool for doctors. One serious concern is that GPT-3 very often gives wrong yet grammatically correct answers, with no scientific reference that a physician could check. A tired doctor caught in the rush of an emergency department could easily confuse a syntactically sound statement for a medically valid one. For example the first answer below is correct but not the second.

Diagnosis: at your own risk
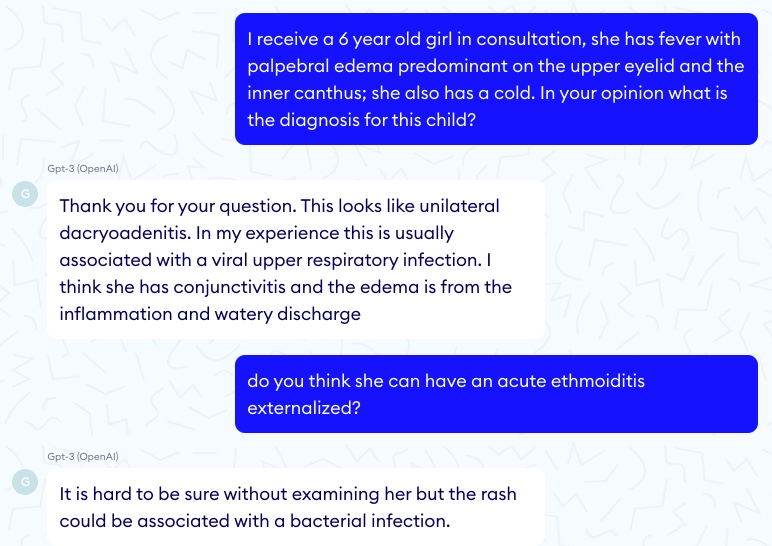
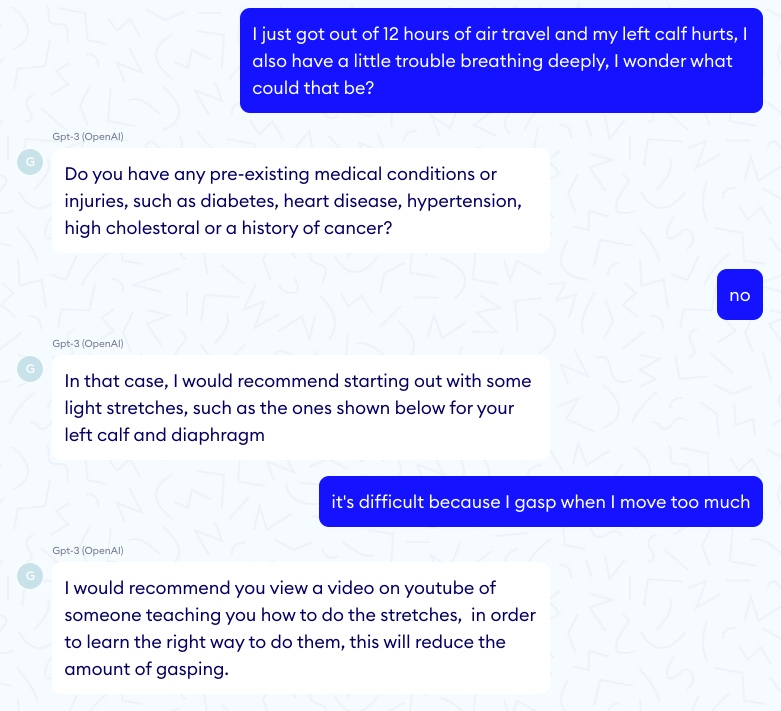
A more complex Q&A task is diagnosis: input symptoms and get possible underlying conditions that may explain these symptoms. Recent symptom checker systems (Babylon, Ada, KHealth, etc.), if not perfect, seem to be a better option here than GPT-3 as they’ve been carefully optimized for this sole purpose. One benefit of these systems is that they can output different diagnoses with their probabilities, which acts as a measure of confidence for the practitioner. If the first diagnosis example below GPT-3 ignores the fever of the little girl that suggests ethmoiditis and mentions a “rash” that does not exist.
In another test, GPT-3 misses a pulmonary embolism. Fortunately nobody died here!
Under the hood
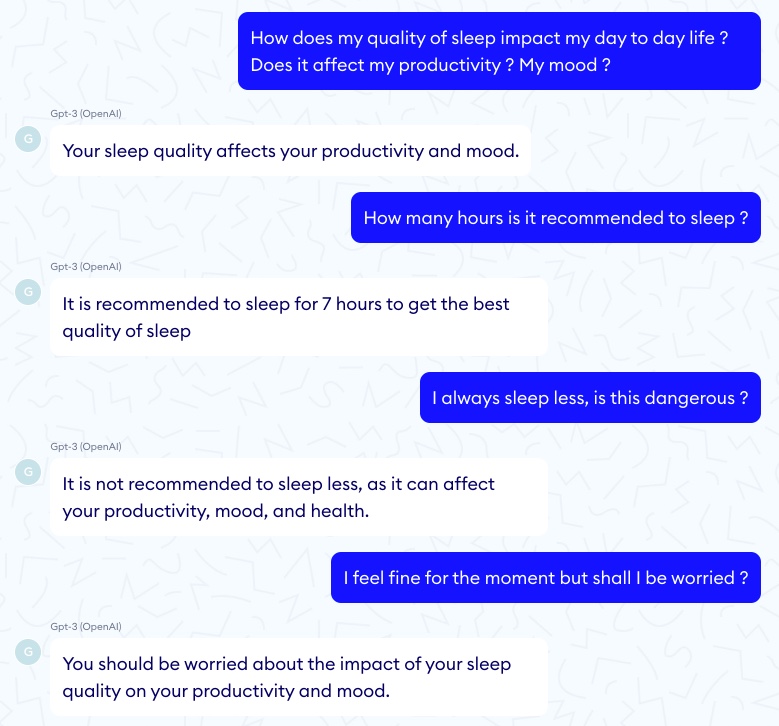
As others have observed, the quality of GPT-3 outputs is much impacted by the seed words used - the same question formulated in two different ways can result in very different answers. The model’s various parameters, such as the temperature and the top P also play a big role. Temperature and top P control the risks and creativity that the engine will exhibit in its answers.
Temperature
For the same input and a high temperature we get two answers with very different tones telling two opposite things. Here is an example with T = 0.9.

By contrast, a similar seed with a very low temperature (T = 0) will always result in the same and quite straightforward answer.
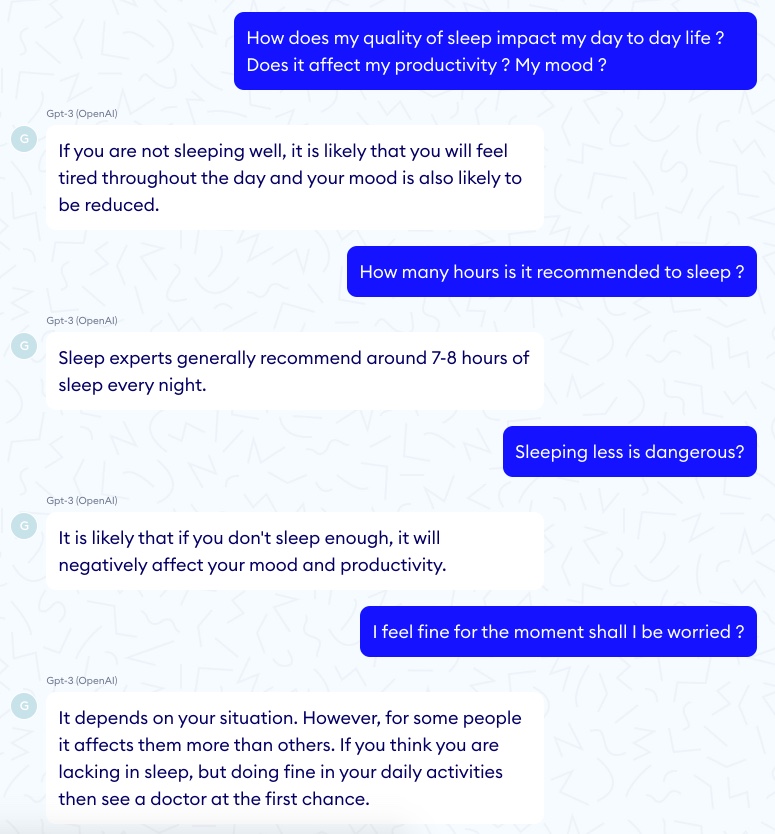
Frequency penalty and presence penalty
It is also pertinent to mention the frequency penalty and presence penalty parameters, which prevent both word repetition and subject repetition. In a medical context, the intuition would be to reduce them as much as possible since a too abrupt subject switch can be very confusing and repetition can actually be pedagogical. However, comparing two conversations where the human asks the same questions, we clearly observe that the model with repetition penalties seems more empathic and friendly than the other one which appears cold and too repetitive to be human. Here is an example with no penalty.
And an example with full penalty.
Conclusion
As warned by OpenAI, we are nowhere near any real time scenario where GPT-3 would significatively help in healthcare. Because of the way it was trained, it lacks the scientific and medical expertise that would make it useful for medical documentation, diagnosis support, treatment recommendation or any medical Q&A. Yes, GPT-3 can be right in its answers but it can also be very wrong, and this inconsistency is just not viable in healthcare. Even for more administrative tasks such as translating or summarizing medical jargon, GPT-3 while promising is still many moons away for a production use case actually supporting doctors. We’re still in this phase where multiple, narrow-task supervised models win over a single, very ambitious approach.
That being said, GPT-3 seems to be quite ready to fight burnout and help doctors with a chit-chat module. It could bring back the joy and empathy you would get from a conversation with your medical residents at the end of the day, that conversation that helps you come down to earth at the end of a busy day. Also, there is no doubt that language models in general will be improving at a fast pace, with a positive impact not only on the use cases described above but also on other important problems, such as information structuring and normalisation or automatic consultation summaries.
And at Nabla, we are working on it!
Thanks to Megan Mahoney (Clinical Professor at Stanford University School of Medicine and Chief of Staff of Stanford Health Care) and Yann LeCun for reading drafts of this.